Introduction
Lorsque je recherche quelque chose sur internet, je me rends souvent compte que le contenu anglais est souvent bien plus fourni que le contenu français.
Même si cela peut paraître évident de part le nombre d'anglophones dans le monde comparé à celui des francophones (de 4 à 5 fois plus nombreux), j'ai voulu démontrer cette hypothèse et surtout la chiffrer.
TLDR : En moyenne, un article anglais sur Wikipedia contient 19% d'informations supplémentaires que son équivalent en français.
Le code source de cette analyse est disponible ici : https://github.com/jverneaut/wikipedia-analysis/
Protocole
Wikipedia est une des plus grande source de contenu de qualité sur le web dans le monde.
Au moment d'écrire cet article, la version anglaise compte plus de 6 700 000 articles uniques contre 2 500 000 seulement pour la version française. Nous allons utiliser ce corpus comme base d'étude.
En utilisant la méthode de Monte-Carlo, nous échantillonnerons des articles aléatoires sur Wikipedia pour chaque langue et compterons la longueur moyenne des caractères de ce corpus. Avec un nombre d'échantillons suffisamment élevés, nous devrions obtenir des résultats proches de la réalité.
Comme l'API Wikimedia ne fournit pas d'API pour obtenir la longueur en caractères d'un article, nous obtiendrons ces informations comme ceci :
- Récupération de la taille en octets d'un grand échantillon d'articles via l'API Wikimedia
- Estimation du nombre d'octets par caractère à partir d'un petit échantillon d'articles avec la méthode de Monte-Carlo
- Récupération de la taille en nombre de caractère d'un grand nombre d'articles à partir du nombre d'octets par caractère obtenus à l'étape 2
Comme nous utilisons la méthode de Monte-Carlo pour estimer le nombre d'octets par caractère, nous aurons besoin d'un nombre d'articles le plus grand possible pour minimiser la déviation par rapport au nombre réel.
La documentation de l'API Wikimedia spécifie ces limitations :
- Pas plus de 500 articles aléatoires par requête
- Pas plus de 50 contenus d'articles aléatoires par requête
En prenant en compte ces limitations et comme compromis entre la précision et le temps d'exécution de nos requêtes, j'ai choisi d'échantillonner 100 000 articles par langue comme base de référence pour la longueur en octets des articles et 500 articles pour évaluer le nombre d'octets par caractère de chaque langue.
Limitations
Actuellement, l'API Wikimedia renvoie son propre format wikitext lorsqu'on lui demande de renvoyer le contenu d'un article. Ce format n'est donc pas du texte brut et est plus proche du HTML. Comme toutes les langues sur Wikimedia utilisent ce même format, j'ai estimé que nous pouvions nous baser dessus sans influencer la direction de nos résultats finaux.
Certains languages sont cependant plus verbeux que d'autres. En français par exemple, nous disons "Comment ça va ?" (15 caractères) contre "How are you?" (12 caractères) en anglais. Cette étude ne prend pas en compte ce phénomène. Si nous voulions le faire, nous pourrions comparer différentes traductions d'un même corpus de livres pour établir une variable de correction de "densité" des languages. Lors de mes recherches, je n'ai pas trouvé de données faisant fois dans ce domaine qui puisse me donner un ratio à appliquer à chaque langue.
J'ai cependant trouvé un papier très intéressant qui compare la densité d'information de 17 différentes langues et la vitesse à laquelle celles-ci sont parlées. La conclusion de celui-ci est que les langues les plus "efficaces" sont parlées moins rapidement que les langues l'étant le moins, arrivant ainsi à une transmission de l'information orale tournant toujours autour des ~39 bits/s.
Intéressant.
Obtenir la longueur moyenne en octet des articles dans chaque langue
Comme énoncé dans le protocole, nous allons utiliser une API de Wikipedia permettant de récupérer 500 articles aléatoires dans une langue donnée.
def getRandomArticlesUrl(locale):
return "https://" + locale + ".wikipedia.org/w/api.php?action=query&generator=random&grnlimit=500&grnnamespace=0&prop=info&format=json"
def getRandomArticles(locale):
url = getRandomArticlesUrl(locale)
response = requests.get(url)
return json.loads(response.content)["query"]["pages"]Ceci nous donne ensuite une réponse du type { "id1": { "title": "...", "length": 1234 }, "id2": { "title": "...", "length": 5678 }, ... } que nous pouvons utiliser pour récupérer la taille en octets d'un grand nombre d'articles.
Ces données sont ensuite retravaillées pour obtenir le tableau suivant :
| Langue | Longueur moyenne | ... |
|---|---|---|
| EN | 8865.33259 | |
| FR | 7566.10867 | |
| RU | 10923.87673 | |
| JA | 9865.59485 | |
| ... |
À première vue, il semblerait que les articles en anglais ont une longueur en octets plus importante que ceux en français. De même, ceux en Russe ont une longueur en octets plus importante que ceux de n'importe quelle autre langue.
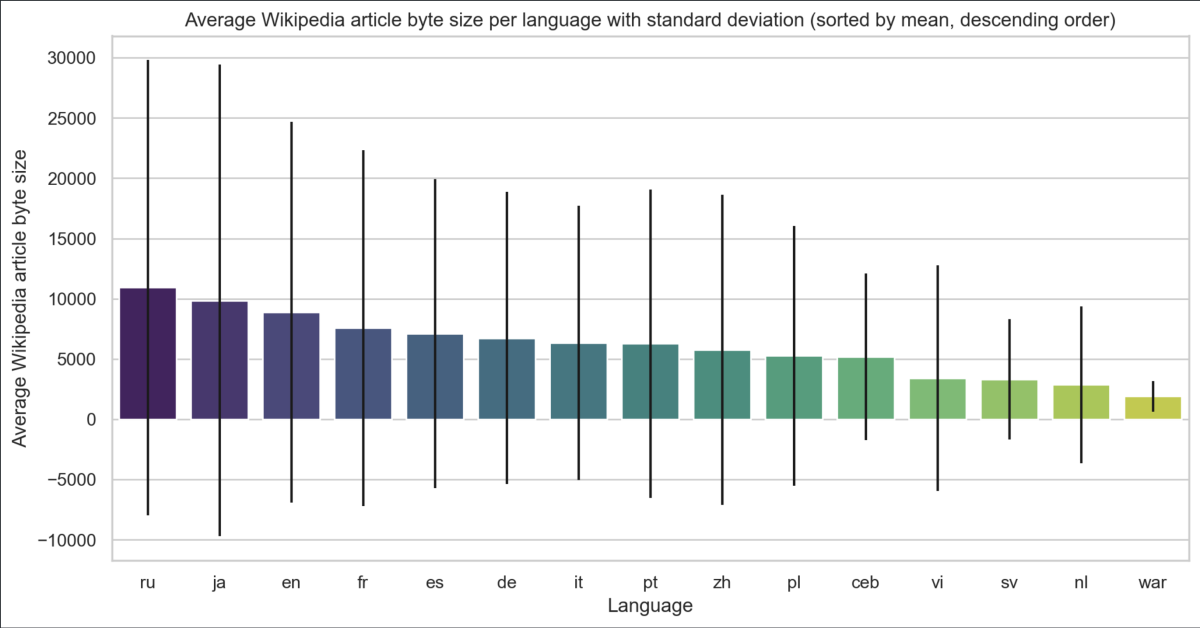
Devons-nous nous arrêter à cette conclusion ? Pas tout à fait. La longueur remontée par Wikipedia étant une longueur en octets, nous devons approfondir un petit peu plus la façon dont les caractères sont encodés pour comprendre ces premiers résultats.
Comment sont encodées les lettres : Une introduction à UTF-8
Qu'est-ce qu'un octet
Contrairement à vous et moi, un ordinateur n'a pas de notion des lettres, encore moins d'un alphabet. Pour lui, tout est représenté comme une succession de 0 et de 1.
Dans notre système décimal, nous allons de 0 à 1, puis de 1 à 2, etc. jusqu'à arriver à 10.
Pour l'ordinateur qui utilise un système binaire, on va de 0 à 1, puis de 1 à 10, puis de 10 à 11, 100, etc.
Voici une table de comparaison pour y voir plus clair :
| Décimal | Binaire |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 1000 |
| 9 | 1001 |
| 10 | 1010 |
| ... |
Apprendre le binaire dépasse largement le scope de cet article, mais vous pouvez voir que plus le nombre devient grand, plus sa représentation binaire est "large" comparée à sa représentation décimale.
Comme un ordinateur a besoin de distinguer les nombres entre eux, il les stocke par petits paquets de 8 unités appelés des octets. Un octet est donc composé de 8 bits, par exemple 01001011.
Comment UTF-8 stocke les caractères
Nous avons vu comment stocker des chiffres, ça se complique un petit peu pour le stockage des lettres.
Notre alphabet latin utilisé dans bon nombre de pays occidentaux utilise un alphabet de 26 lettres. Ne pourrions-nous pas simplement utiliser une table de référence ou chaque nombre de 0 à 25 correspond à une lettre ?
| Lettre | Index | Index binaire |
|---|---|---|
| a | 0 | 00000000 |
| b | 1 | 00000001 |
| c | 2 | 00000010 |
| ... | ||
| z | 25 | 00011001 |
Mais nous avons plus de caractères que des simples lettres minuscules. Dans cette simple phrase, nous avons aussi des majuscules, des virgules, des points, etc. Une liste a alors été standardisée pour tous les contenir dans un seul octet, le fameux standard ASCII.
À l'aube de l'informatique, celui-ci était suffisant pour des usages basiques. Mais comment faire si nous souhaitons utiliser d'autres caractères ? Comment faire pour écrire avec l'alphabet cyrillique (33 lettres) ? C'est pour cette raison que le standard UTF-8 a été créé.
UTF-8 veut dire Unicode (universal coded character set) Transformation Format - 8 bits. C'est un système d'encodage qui permet à un ordinateur de stocker des caractères sur un ou plusieurs octets.
Pour qu'il sache le nombre d'octets sur lesquels sont réparties les données, les premiers bits de cet encodage sont utilisés pour le lui indiquer.
| Premiers bits en UTF-8 | Nombre d'octets utilisés |
|---|---|
| 0xxxxxx | 1 |
| 110xxxxx ... | 2 |
| 1110xxxx ... ... | 3 |
| 11110xxx ... ... ... | 4 |
Les bits suivants ont eux aussi leur utilité, mais encore une fois cela dépasse le scope de cet article. Retenons juste qu'au minimum, un seul bit peut être utilisé comme signature dans le cas où notre caractère rentre dans les x1111111 = 127 possibilités restantes.
Pour l'anglais qui n'utilise pas d'accents, nous pouvons supposer que la plupart des caractères d'un article seront encodés de cette manière et que donc la moyenne des octets par caractère devrait être proche de 1.
Pour le français qui utilise des accents, des cédilles, etc., nous supposons que ce nombre sera plus élevé.
Enfin, pour les langues avec un alphabet plus étendu comme le russe et le japonais, nous pouvons nous attendre à un nombre d'octets élevés ce qui nous donne un début d'explication des résultats obtenus précédemment.
Obtenir la longueur moyenne en octets des caractères des articles pour chaque langue
Maintenant que nous avons compris ce que voulait dire la valeur renvoyée précédemment par l'API de Wikipedia, nous voulons donc calculer le nombre d'octets par caractère de chaque langue pour pouvoir ajuster ces résultats.
Pour se faire, nous utilisons une autre façon d'utiliser l'API de Wikipedia qui nous permet cette fois-ci d'obtenir le contenu des articles ainsi que leur longueur en octets.
Pourquoi ne pas avoir utilisé cette API directement ? Cette API ne renvoie que 50 résultats par requête là où la précédente en renvoie 500. Dans un même laps de temps, nous pouvons donc obtenir 10x plus de résultats de cette manière.
Plus concrètement, si les appels à l'API prenaient 20 minutes avec la première méthode, ils en prendraient 3h20 de cette façon.
def getRandomArticlesUrl(locale):
return "https://" + locale + ".wikipedia.org/w/api.php?action=query&generator=random&grnlimit=50&grnnamespace=0&prop=revisions&rvprop=content|size&format=json"
def getRandomArticles(locale):
url = getRandomArticlesUrl(locale)
response = requests.get(url)
return json.loads(response.content)["query"]["pages"]Une fois ces données synthétisées, voici un extrait de ce que nous obtenons :
| Langue | Octets par caractère | ... |
|---|---|---|
| EN | 1.006978892420735 | |
| FR | 1.0243214042939228 | |
| RU | 1.5362439940531318 | |
| JA | 1.843857157700553 | |
| ... |
Notre intuition était donc la bonne, les pays avec un alphabet plus étendu faussent les données de part la façon dont leurs contenus sont stockés.
Nous voyons également que le français utilise plus d'octets en moyenne pour stocker ses caractères que l'anglais comme nous l'avions supposé précédemment.
Résultats
Nous pouvons désormais corriger les données en passant d'une taille en octets à une taille en caractères ce qui nous donne le graphique suivant :
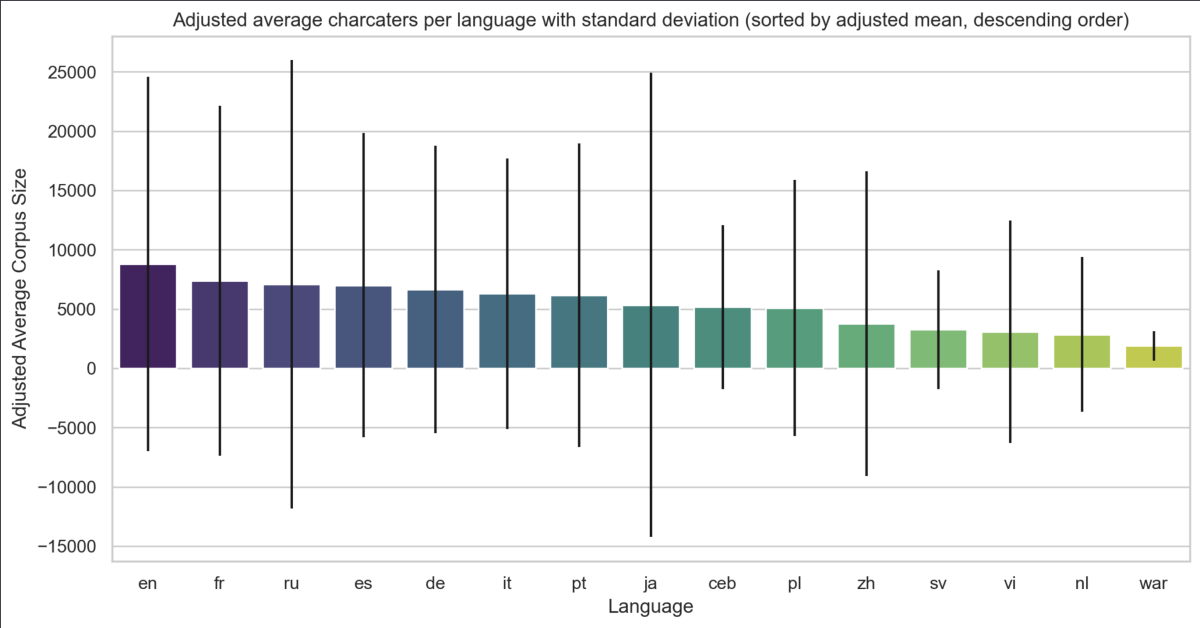
Notre hypothèse est donc confirmée.
En moyenne, l'anglais est la langue avec le plus de contenu par page sur Wikipedia. Elle est suivie du français, puis du russe, de l'espagnol et de l'allemand.
L'écart type (affiché avec les barres noires) est grand sur ce jeu de données ce qui signifie que la taille des contenus est très étendue de l'article le plus court à celui le plus long. Il est donc difficile d'établir une vérité générale sur l'ensemble des articles, mais cette tendance semble tout de même en adéquation avec mon expérience personnelle de Wikipedia.
Si vous voulez tous les résultats de cette expérience, j'ai également édité cette représentation qui compare chaque langue avec pour chacune son pourcentage de contenu en plus/en moins par rapport aux autres.
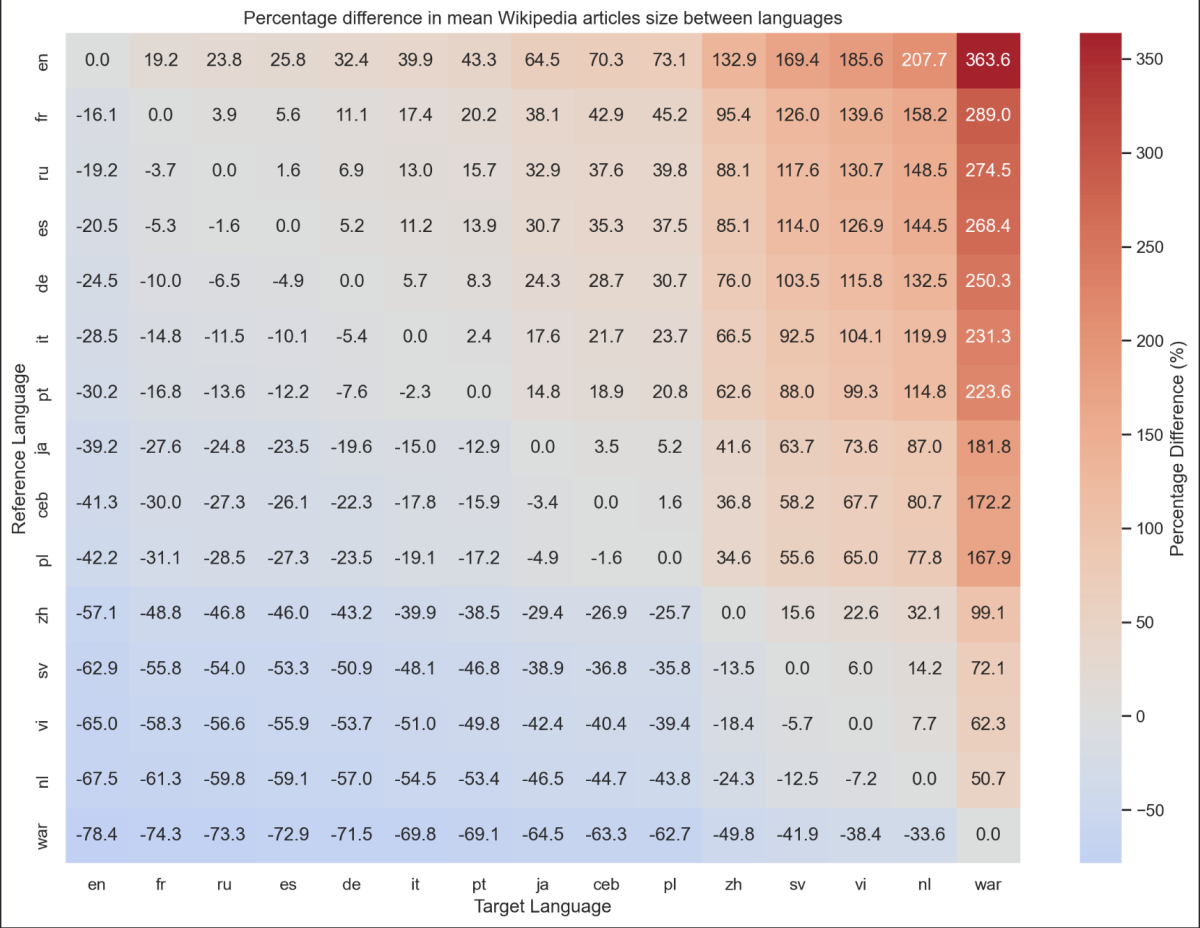
Grâce à celui-ci, nous retrouvons donc notre conclusion qu'en moyenne, un article anglais sur Wikipedia contient 19% d'informations supplémentaires que son équivalent en français.
Le code source de cette analyse est disponible ici : https://github.com/jverneaut/wikipedia-analysis/
